

DuckDB is an in-process OLAP DBMS written in C++ blah blah blah, too complicated. Let’s start simple, shall we? DuckDB is the SQLite for Analytics. It has no dependencies, is extremely easy to set up, and is optimized to perform queries on data. In this hands-on tutorial, you will learn what DuckDB is, how to use it, and why it is essential for you. Ready? Let’s go 👇
DuckDB use cases
Why DuckDB? As a data analyst or a data scientist, a typical workflow is to load data from a CSV file or an S3 bucket, perform preprocessing steps, and run your analysis. To achieve those things, you pull up a Jupyter notebook, import Numpy and Pandas, and then execute your queries. Interestingly, if you look at your operations, you usually perform database operations such as joins, aggregates, filters, etc. But, instead of using a relational database management system (RDBMS), you use Pandas and Numpy.
The question is, why? Setting up a database and loading data in it can be a painful, slow, and frustrating experience. If it were easy, you would have everything to gain by using an RDBMS.
Say “welcome” to DuckDB! 👋
DuckDB is the easiest and fastest way to analyze data with a DB.
Why DuckDB?
Here are a few benefits of using DuckDB
Local
First, DuckDB is an in-process single-file database with no external dependencies. What does that mean? Unlike Postgres, there is no client/server to set up or external dependencies to install. In addition, the data transfer to/from the client is slower than it should be, especially for local installations. On the other hand, DuckDB is embedded in the host application process and manages a database stored in a single file. There is no client/server, and it is straightforward to install. If you need to run a DB for local data analysis, it’s the way to go!
Performances
Second, DuckDB is highly optimized for analytical query workloads (OLAP). Because it is columnar-oriented DB (along with other optimizations), complex-long-running queries to aggregate, join or read data become blazingly fast! It’s easy to claim that ~90% of big data workloads can be handled on a single machine without any setup or computation pains with DuckDB. That’s not the case with Pandas. Pandas cannot leverage CPU cores to parallelize computations, making them slow to complete. It operates entirely in memory leading to out-of-memory errors if the dataset is too big.
SQL
Whether you like it or not, SQL is more alive than ever. DuckDB supports a fairly advanced SQL command set, such as window functions and aggregates. It provides transactional guarantees (ACID properties) and uses the Postgres API. Forget about the ugly and slow Panda’s manipulations. You can replace all of them with elegant SQL (it offers some additions on top of SQL to make it more friendly, as shown here). Finally, DuckDB has a Python Client and shines when mixed with Arrow and Parquet.
To sum up, DuckDB is an actively developed open-source, embeddable, in-process, and column-oriented SQL OLAP RDBMS. Perfect for data practitioners who want to perform local analytical workloads easily and quickly.
DuckDB limitations
DuckDB is designed to run on a single machine. That means your data has to fit with that single machine; otherwise, it doesn’t work. In reality, you can use powerful computers that will be enough for 99% of your workload. That shouldn’t be an issue unless you process terabytes of data daily. By looking at AWS offerings, you can have an instance with up to 1,952GB of memory and 128 vCPUs.
Another limitation is that DuckDB is not a multi-tenant database. Having different people with different teams, developing models, and sharing data on the database will be very challenging. However, when you integrate the DB with other tools such as Airflow, S3, Parquet, and dbt, you can get a robust data ecosystem with which teams can efficiently work.
This is not a limitation per se, but DuckDB is not a transactional database and should not be used that way.
DuckDB vs SQLite
While SQLite is a general-purpose database engine, it is primarily designed for fast online transaction processing (OLTP).
SQLite is:
- Cross-platform: A SQLite database is stored in a single file.
- Compact and self-contained: Available as a small file. It doesn’t require installation or configuration and has no external dependencies.
- Reliable: Often used in mission-critical applications such as flight software.
- Fast: Can support tens of thousands of transactions per second.
- ACID guarantees: Transactions are atomic, consistent, isolated, and durable
Those features above are the same for DuckDB. That’s why it claims to be the “SQLite for analytics.” So what are the differences?
DuckDB is built from the ground up for in-process OLAP employing columnar storage, vectorized query processing, and multi-version concurrency control optimized for ETL operations. On the other hand, SQLite uses a row-oriented storage format, meaning that SQL queries act on individual rows rather than batches of rows, as in vectorized query processing, giving poorer performances for OLAP queries.
To sum up, they both share many characteristics. However, DuckDB is optimized for queries that apply aggregate calculations across large numbers of rows, whereas SQLite is optimized for fast scanning and lookup for individual rows of data. If you need to perform analytical queries, go with DuckDB; otherwise, use SQLite.
DuckDB with Python
Time to play with DuckDB. First, create a duckdb directory, download the following dataset , and extract the CSV files in a dataset directory inside duckdb. This dataset contains fake sale data with columns order ID, product, quantity, etc.
To use DuckDB, you must install Python packages. To avoid conflicts with already installed packages on your machine, it’s a best practice to create a Python virtual environment. For that, open your terminal and type the command python3 -m venv venv. Activate the environment by executing source venv/bin/activate and run a cell in VS Code (or any IDE). To create a cell with VS Code type:
# %%
Click “Run Cell” and ensure you select the Python virtual environment as shown at the top right corner in the image below:

Install DuckDB and requirements
With the Python virtual environment ready, create a new file requirements.txt. That file contains the Python packages DuckDB needs to work as well as DuckDB itself.
duckdb==0.9.0
pandas==2.1.1
seaborn==0.13.0
matplotlib==3.8.0Save the file and run the command pip install -r requirements.txt to install the dependencies.
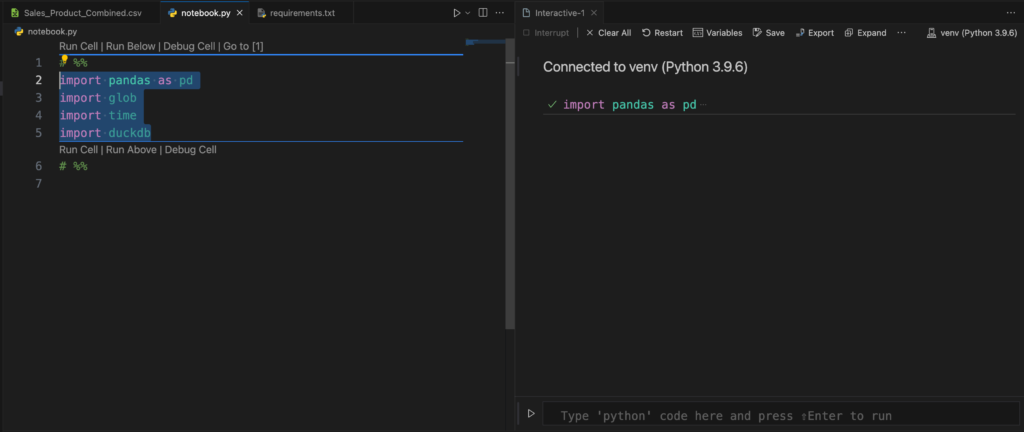
Go back to the notebook and add the following imports in the first cell:
# %%
import pandas as pd
import glob
import time
import duckdbRun the cell, and you should see that:
Create a DuckDB connection
To initialize DuckDB, execute in a new cell:
conn = duckdb.connect()By default, connect with no parameters creates an in-memory database globally stored inside the Python module. If you close the program that initiates the connection, you lose the database and the data. On the other hand, if you want to persist the data, pass a filename to connect so it creates a file corresponding to the database.
conn = duckdb.connect("my_db.db")Last, in case you desire to query an existing database without writing data to it, pass the read_only parameter as shown below:
conn = duckdb.connect("my_db.db", read_only=True)For now, keep the first option to create an in-memory database.
How to query data with DuckDB and Python
In a new cell, add and execute the following code:
conn.sql("""
SELECT *
FROM 'dataset/*.csv'
LIMIT 10
""")conn.sql executes SQL queries to your database. In the example above, DuckDB loads all CSV files in the dataset directory and prints the first ten rows. Under the hood, DuckDB uses the CSVLoader to infer columns and types automatically. As you can see, it’s easy. Give the path to your CSV files, and you can query them as if you were querying an SQL table. Remember that DuckDB is compatible with many file types, such as Parquet, Hive partitions, JSON, and more. Take a look at the documentation here.
How to retrieve data from a DuckDB query
Being able to query data is good, but retrieving data from a query is even better! DuckDB provides multiple methods that you can use to efficiently retrieve data, such as:
- fetchnumpy() fetches the data as a dictionary of Numpy arrays
- df() brings the data as a Pandas Dataframe
- arrow() fetches the data as an Arrow table
- pl() pulls the data as a Polars Dataframe.
Ultimately, choosing the best method that suits your needs is up to you. As a best practice, do not use fetch_one or fetch_all as they create a Python object for every value returned by your query. If you have a lot of data, you can have a memory error or poor performance.
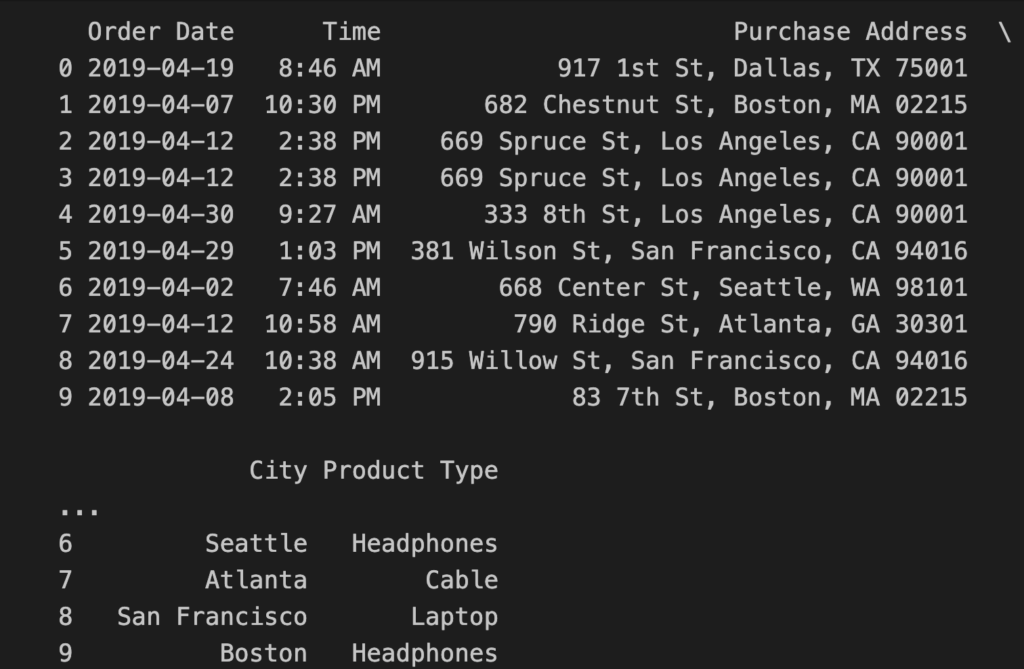
Let’s retrieve the data as Pandas Dataframe by changing the previous cell like this:
df = conn.sql("""
SELECT *
FROM 'dataset/*.csv'
LIMIT 10
""").df()Add a new cell to print the Dataframe on the standard output:
print(df)Then, run the two cells, and you will see the following output:
How to create a Table from a Dataframe
Imagine you want to know the column types of a Dataframe. For that, you could run:
print(conn.execute("DESCRIBE df").df())But this query gives the following error:
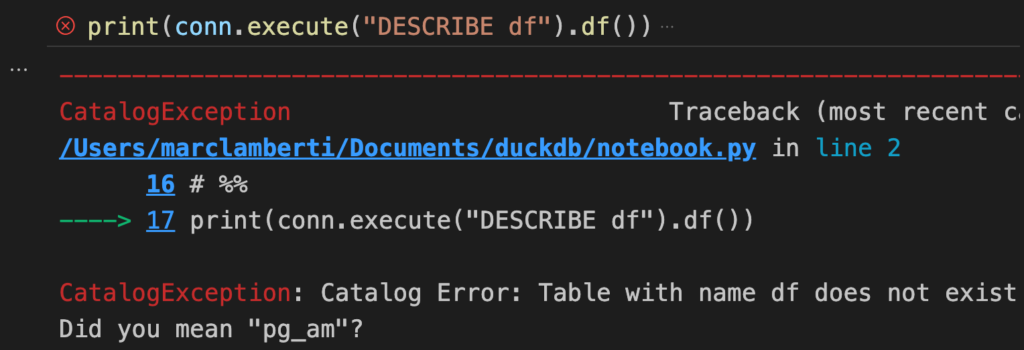
Why that? Well, because the table df doesn’t exist yet. Until now, you’ve been querying the files directly using DuckDB. Another way is to register the output of the previous query as a virtual table so you can query the data using the usual SQL table features. How? Simple!
conn.register("df_view", df)
print(conn.execute("DESCRIBE df_view").df())That creates a virtual table df_view from the Dataframe df. Rerunning the cell will give you the expected output:
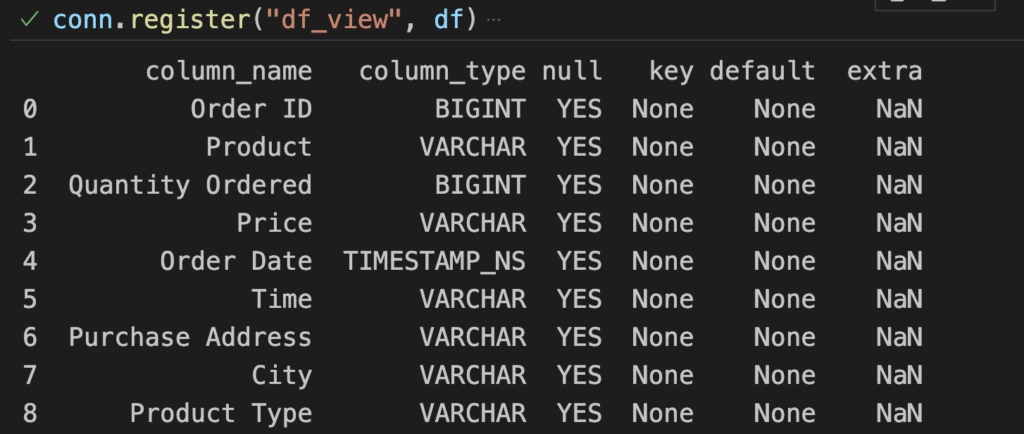
Voila! 🤩
DuckDB in action!
That’s it for this tutorial. However, if you would like to see the rest and discover how to clean data, query Pandas Dataframes, apply filters on columns, exclude columns, export the data into a Parquet file, and more, I made the following video for you 👇 You can start around 14:00. Enjoy!
Conclusion
DuckDB saves you time by being easy to use and efficient at querying any data. Instead of going through a classic RDBMS to load and query your data, simply use DuckDB. Remember that for most of your use cases, you may not need a massive setup with 100 CPUs and 100Gb of memory. In addition, DuckDB offers compatibility with many well-known packages such as Pandas, Arrow, Parquet and Numpy, which makes it convenient for making operations between them. Enjoy and see you for another tutorial!