

What is Apache Airflow? Perhaps your colleagues or YouTube videos have mentioned it. Maybe your job requires you to use it, but you’re unsure what it is. In this article, you will learn everything about what Airflow is, what it isn’t, and its core concepts and components. But, before answering this question, we need a proper understanding of what an “orchestrator” is. Let’s go!
What is an orchestrator? The analogy!
Let’s say you want to make tasty chocolate cake. That cake doesn’t get magicked into existence; it involves a process – a step-by-step recipe you carefully need to follow; otherwise, you will get something different. First, you need sugar, flour, eggs, and chocolate ingredients. Then, you must mix them in a specific order while applying certain transformations, like mixing eggs with the flour, breaking the chocolate into pieces, etc.
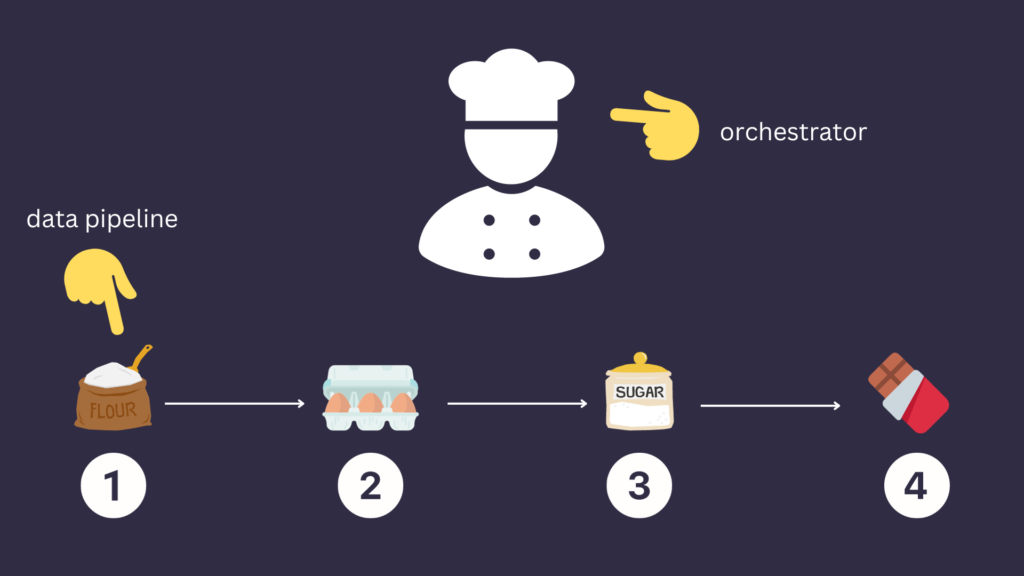
To ensure that this recipe is followed correctly to yield that delicious chocolate cake, we need someone who carefully achieves the required steps in the correct order, in the right way, and at the right time. This is… YOU! You are the chief who manages all of that to get this chocolate cake. Stemming from this analogy, “you” is the orchestrator in data orchestration, and the recipe is the data pipeline. Thus, the orchestrator’s prime objective is to schedule tasks appropriately for a valuable and usable output at the end. Now you know what an orchestrator is, we can move on to the question, “What is apache airflow?”.
What is Apache Airflow?
Digging into the official definition, you will see that Airflow is noted as an open-source platform that programmatically authors, schedules, and monitors workflows. It was created in 2014 by Airbnb and has since been widely adopted by the data engineering community, primarily as it was the first orchestrator allowing to author data pipelines programmatically. Alright, let’s dive into Airflow benefits.
Airflow Benefits
There are four main advantages of using Apache Airflow:
Dynamic and Pythonic: Everything in Airflow is in Python, offering you a creative edge in developing dynamic workflows. You can inject data at runtime, create data pipelines from YAML files, and generate tasks dynamically. As long as you know Python, you can build data pipelines and fully utilize AIrflow.
Highly Scalable: You can scale Airflow as much as you want. Starting with just a few tasks to thousands of tasks thanks to the support of various systems such as Dasks, Kubernetes, or Celery. Obvsiouly, that depends on the resources available to you and… the budget.
Customizable: You can customize Airflow to meet your specific needs. You can change the user interface, add new views, create your operators (tasks), or even your way of executing tasks. You will never feel stuck waiting for someone else to update or add something – customize it as necessary!
User Interface: OK, I love the user interface. Yes, it can be better, but still, I find it very useful! The user-friendly interface lets you easily monitor and interact with DAGs and tasks. Examples are the calendar view to identify patterns over time, the grid view for tracking historical tasks and dag states, or the cluster view to monitor your Airflow instance out-of-the-box.
Now you know what is Apache Airflow from a benefit
Airflow Concepts
Airflow has a few concepts to know. Let’s discover the most important ones.
What is a DAG?
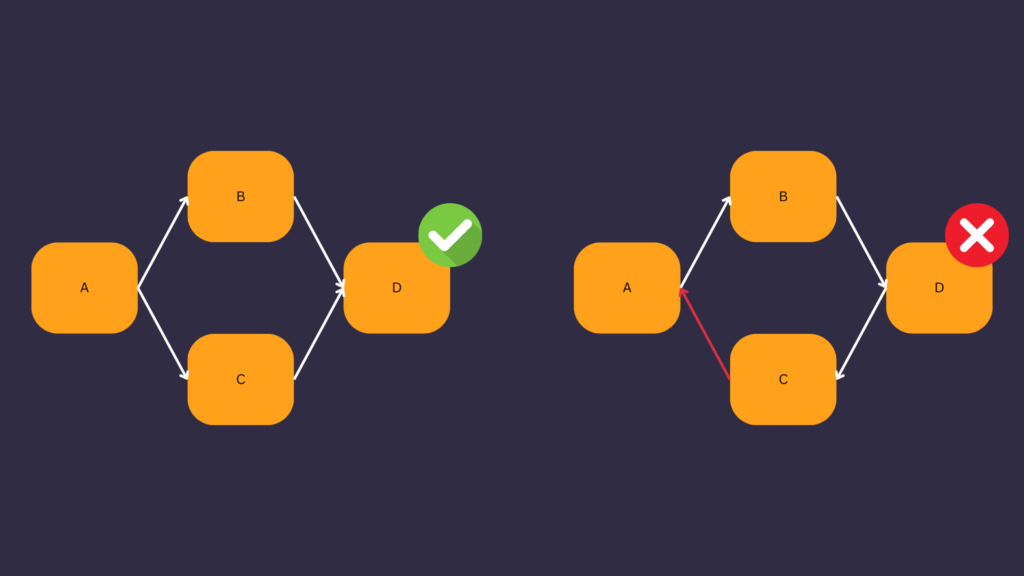
A DAG means Directed Acyclic Graph. A DAG is a directed graph with no directed cycles corresponding to a workflow (data pipeline) in Apache Airflow. When you create a data pipeline, you create a DAG.
The image below depicts a valid DAG on the left and an invalid DAG on the right because there is a cycle.
Look at the tutorial here to learn how to create your first data pipeline.
What is a Task?
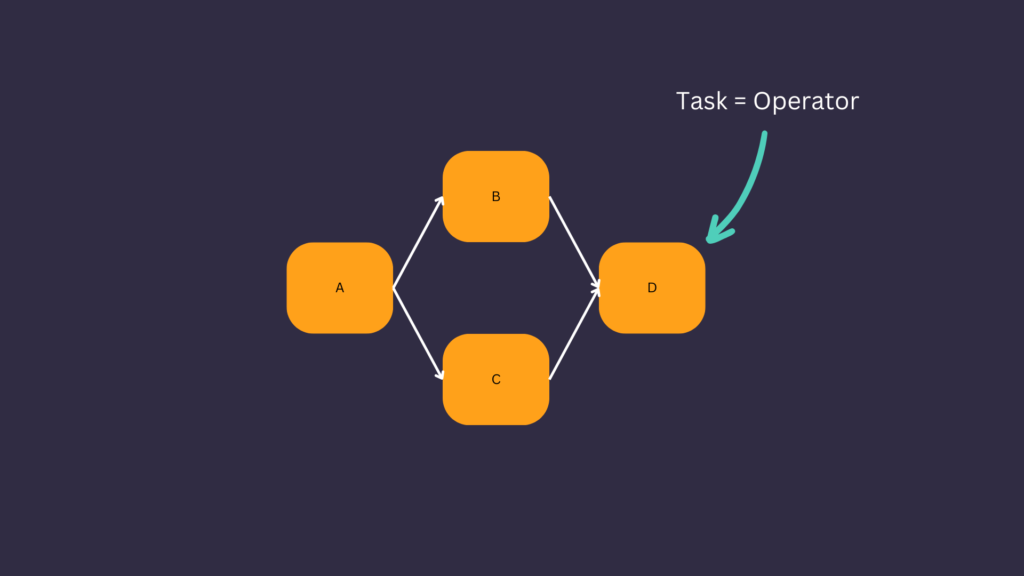
A node is a task in a DAG. A task is an Operator in Apache Airflow. Airflow provides many operators such as the PythonOperator to execute Python functions, the BashOperator to execute bash commands, the SnowflakeOperator to request Snowflake, and more. You can see the list here.
What is a DAG run?
When Airflow triggers a DAG, it creates a DAG run. Therefore, a DAG run is an instance of a DAG at a specific time. A DAG run can have four states: Queued, Running, Failed, and Success.
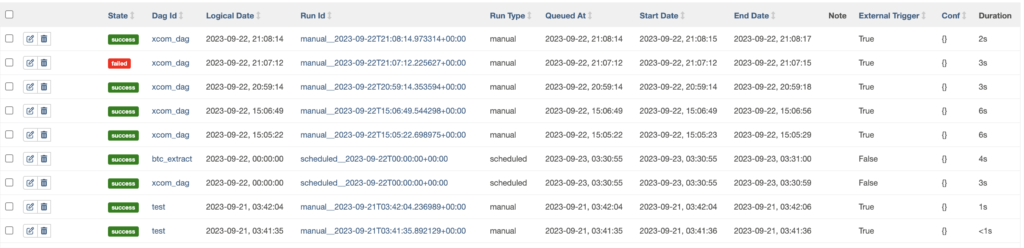
A DAG run has information such as:
- A state: The state of the DAG run, Success, Failed, Running, and Queued.
- A DAG ID: The unique identifier of the DAG represented by the DAG run.
- A Logical Date: The data interval end date or the execution date of the DAG run.
- A Run Id: The unique identifier of the DAG run.
- A Run type: How the DAG was triggered, manual, or scheduled.
And more.
What is a Task Instance?
When Airflow triggers a task, it creates an associated task instance object. A Task Instance can have many states such as: None, Scheduled, Queued, Running, Success, Failed, Shutdown, Up for retry, and more.
Airflow components
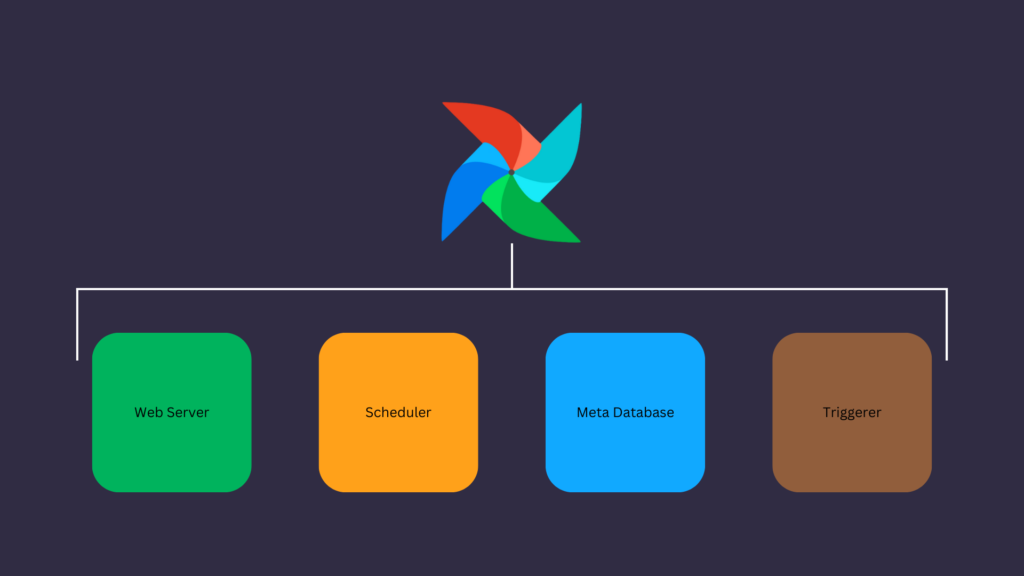
Airflow has four main components:
- The Webserver: Provides the User Interface
- The Scheduler: Schedule DAG runs and Task instances at a specific interval in order.
- The Meta database: Database compatible with SqlAlchemy. Airflow stores metadata in it (DAG runs, XComs, Task instances, etc.
- The Triggerer: Airflow uses this component to manage a particular type of Operators called the Deferrable Operators.
Only the Scheduler and the meta database components are required to run Airflow.
What Airflow is not?
It is also essential to understand what Airflow is not – it’s neither a streaming solution nor a data processing framework. It is designed to handle batch-oriented workflows, and while it can process data, large data volumes are more efficiently and effectively handled by data processing frameworks like Spark than Airflow.
Conclusion
In wrapping up, I hope this detailed insight has given you a clearer understanding of Apache Airflow. What is Apache Airflow, what it is not, and more. Looking forward to embarking on another knowledge journey with you.